My first AI

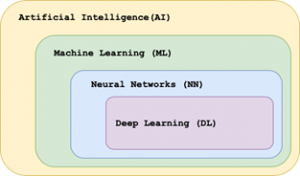
Nowadays a lot of people use and benefit from different Artificial Intelligence applications everyday: voice assistants like Siri, opening the phone with Face ID, Netflix or music recommendations. And even though more and more people are interested in understanding how AI works, there is still some confusion between the terms Artificial Intelligence, Machine Learning, Neural Networks and Deep Learning. Each of these concepts is a subset of another. Artificial Intelligence is a science, that tries to find a solution to the problems that are usually considered to be only solvable by humans. Machine Learning is a set of algorithms that can automatically learn to solve a problem and improve from experience. Neural Networks are just one type of Machine Learning algorithms. And Deep Learning includes deep Neural Networks with 3 or more hidden layers.
So why is Machine Learning getting so popular even though it was around since 1970s? The reason is simple: It is becoming possible and successful due to the growing amounts of available data and powerful computational capabilities.
What do you need to start?
- Data, a lot of it. As mentioned earlier, algorithms learn from experience, so you will need a lot of examples for a machine to “understand” the concept.
- Programming skills. Not only to design models, like Neural Networks or apply classical ML algorithms, but also to be able to prepare, manipulate and evaluate raw data and results of your training.
- NN–Framework. If you are interested in Neural Networks and Deep Learning, you are going to need a specialized framework designed for this purpose. There are multiple popular frameworks out there.
- Data
Currently it became much easier to acquire large amounts of data of any kind, whether you are looking for medical data, images, datasets special for autonomous driving, sentiment analysis or natural language processing. A lot of big companies and institutions make their collected data available, such as Google’s Open Images, containing over 10 million images, Amazon’s Reviews with more than 45 million entries, MIT AGE Lab autonomous driving dataset, etc. There are a lot of dataset finders like Google Dataset Search, that can help you find a dataset that fits your problem.
Machine learning depends heavily on data. So even though there are plenty of different datasets of any kind available, besides finding the right data, you will still need to prepare it. Data preparation for Machine Learning could be considered a science itself, it is mostly done by Data Scientists. The preprocessing needed fully relies upon the problem you want to solve and what kind of algorithm you are using. Generally, any kind of data needs to be validated, i.e., you need to ensure that it meets the desired data metrics, like quality, quantity, variance, density, etc. Preprocessing also includes handling null values, standardization, handling outliers and multicollinearity. If there is not enough data or it is too uniform, you could use data augmentation – synthetically enlarge your dataset, for example, images can be rotated, scaled, flipped, cropped, zoomed or the color can be manipulated (exposure, color intensity). And because we are working with large amounts of data, the simplest way to do all this work would be to use the magic of programming. All of this is usually shown and explained in the Data Science and Machine Learning courses.
- Programming
You probably already know, that to get into AI and Machine Learning, you need to learn how to program, and you probably also already heard about Python. But why is Python a go-to programming language when it comes to Machine Learning? First of all, Python is very appealing to developers because it is easy to learn and offers readable code. Because of its popularity it also has a lot of open-source libraries and extensive community support.
All of this makes it perfect for beginner developers and for those interested in Artificial Intelligence, as Python provides some very powerful libraries for work with data and machine learning algorithms, such as scipy, scikit-learn (ML), numpy, pandas (data manipulation and organization), opencv (Computer Vision), matplotlib (visualization) and specialized frameworks for Deep Learning like Tensorflow and PyTorch. There is a lot of learning material on Python online and in particular on Machine Learning with Python. If you are new to Python, then it is definitely worth it to try out some beginner Data Science or Machine learning with Python course, as they always start with basics.
- DL-Frameworks
There are plenty of Deep Learning platforms supporting different programming languages, like Python, C++, Java or R. Although the most well-known for Python are TensorFlow and Pytorch, both are free and open source. What is the difference and with which one to start?
TensorFlow is developed by Google and is widely used in the industry. One of the most well-known applications using TF is Google Translate. Google has a beginner as well as an advanced tutorial introducing both ML and TF. But when starting with TensorFlow in context of Neural Networks, it makes sense to start with Keras. Keras is a high-level API built on top of TensorFlow, which is still used for back-end. This means, that it makes easier for the user to get into Deep Learning without having to learn the details of algorithms. Keras supports all the major types of layers: fully connected, convolutional, pooling, dropout, recurrent etc. The modular nature of Keras makes it great for beginners or for prototyping. But because it is very high-level, it is not very customizable, so if you want to make use of the more low-level features, you’ll have to explore TensorFlow more.
PyTorch is developed by Facebook’s AI Research lab and is gaining popularity in the industry in the last years. Tesla Autopilot is an example of popular software built on top of PyTorch. PyTorch offers a comparatively lower-level API than Keras, which makes the Deep Learning models more flexible, giving the user the space for experiments. Here you can design custom layers and look into the numerical algorithms in further detail, which can encourage deeper understanding of the deep learning concepts.
Both frameworks are serious deep learning tools and are extensively used in the industry. The choice ultimately depends on your preferences, needs and goals. The simplicity of Keras is a clear advantage for a beginner, which makes it a perfect tool for creating your first end-to-end deep learning neural network. If you are somewhat familiar with the mathematics of the deep learning, PyTorch may be more interesting to you as it offers more flexibility and more thorough insight into the fundamentals of deep learning.
Two code snippets are attached below: this is the same network defined in Keras and in Pytorch with following training. It is obvious that the Keras code is much shorter and more understandable, training only requires a couple of lines and validation can be included in the workflow with only one parameter. Whereas in PyTorch example, there has to be defined a class for a Neural Network with its architecture, the training and validation (not in the code) have to be explicitly defined, which requires some more understanding, but also allows more creativity.
TensorFlow with Keras
input_shape = (28, 28, 1)
model = Sequential()
model.add(Conv2D(28, kernel_size=(3,3), input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation=tf.nn.relu))
model.add(Dropout(0.2))
model.add(Dense(10,activation=tf.nn.softmax))
model.compile(
optimizer=keras.optimizers.RMSprop(),
loss=keras.losses.SparseCategoricalCrossentropy(),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
training = model.fit(x_train, y_train, batch_size=64, epochs=10,
validation_data=(x_val, y_val),
Pytorch
class NeuralNet(nn.Module):
def __init__(self):
super(NeuralNet, self).__init__()
self.conv = nn.Conv2d(1, 28, kernel_size=3)
self.pool = nn.MaxPool2d(2)
self.hidden= nn.Linear(28*13*13, 128)
self.drop = nn.Dropout(0.2)
self.out = nn.Linear(128, 10)
def forward(self, x):
x = nn.ReLU(self.conv(x))
x = self.pool(x)
x = x.view(x.size(0), -1)
x = nn.ReLU(self.hidden(x))
x = self.drop(x)
x = self.out(x)
return x
train_loader=DataLoader(trainset, batch_size=64, shuffle=True)
def train():
model.train()
for i, (image, target) in enumerate(train_loader):
optimizer.zero_grad()
loss = F.cross_entropy(model(image), target)
loss.backward()
optimizer.step()
return loss
model = NeuralNet()
for i in range(epochs):
loss = train()
First try
Linear Regression
Linear regression is a good example of a simple classical Machine Learning algorithm. We are going to model the dependency of salary from years of experience. There are a couple of steps required before fitting the model itself to prepare the data and some after to visualize the results.
- Loading libraries & data: we are using pandas for data management, matplotlib for visualization and sklearn as a Machine Learning library. After reading the dataset into a DataFrame, we can display first couple of rows to take a look at the data: there are only 2 columns containing Years of experience and Salary.
dataset = pd.read_csv(’salary_data.csv‘)
print(dataset.head())
| YearsExperience | Salary | |
| 0 | 1.1 | 39343.0 |
| 1 | 1.3 | 46205.0 |
| 2 | 1.5 | 37731.0 |
| 3 | 1.7 | NaN |
| 4 | 2.0 | 43525.0 |
- Preprocessing: as this is a very simple dataset, there isn’t much of preprocessing needed. Features could be normalized, but sklearn takes care of it for us.
- Another problem that we see is the NaN value in the Salary column. There are a lot of ways to deal with missing values and the choice usually depends on the data. We are going to be using the mean of the column to fill it in. You can try and display the head of the data frame again and check the entry.
- The independent variable array X (features) and independent variable array y (targets) are extracted from the data frame.
- Furthermore, data has to be split into train and test sets, because otherwise our Linear Regression model will be overfit to the data that we train it with. This way we can evaluate how it performs on new data. As a rule of thumb 80/20 or 70/30 ratio can be used.
dataset[‚Salary‘].fillna((dataset[‚Salary‘].mean()), inplace=True)
print(dataset.head())
X = dataset.iloc[:, :-1].values # features
y = dataset.iloc[:,1].values # targets
X_train, X_test, y_train, y_test =
train_test_split(X,y,test_size=0.3,random_state=0)
- Fitting the Linear Regression: first, an object of class Linear Regression is declared, but it doesn’t have anything to do with our dataset yet. To ‘adjust’ the parameters to our problem, we use the fit function on our train set.
model = LinearRegression()
model.fit(X_train,y_train) # get linear equation for data
- Validation: by using the function predict on the test set features, we get the predictions made by the trained model. There are different metrics for evaluation of the performance of Linear Regression, we are using the Mean Absolute Error (MAE), because it is easier to interpret. The MAE of 65 means, that the average difference between predicted and real salary with given experience is 6206.65. Our model performs well, considering that the values of salary range from 37 to 122 thousand.
y_pred = model.predict(X_test)
print(mean_absolute_error(y_test,y_pred)) # MAE = 6206.65
- Visualization: by using the scatter and plot functions, both initial data and the resulting linear function can be visualized. The code shows how to do it for the train dataset and the resulting plot, but you can also try it for the test data.
plt.scatter(X_train, y_train, color=’red‘) # raw data
plt.plot(X_train, model.predict(X_train), color=’blue‘) # regression
plt.title(„Salary vs Years of experience (Training set)“)
plt.xlabel(„Years of experience“)
plt.ylabel(„Salaries“)
plt.show()
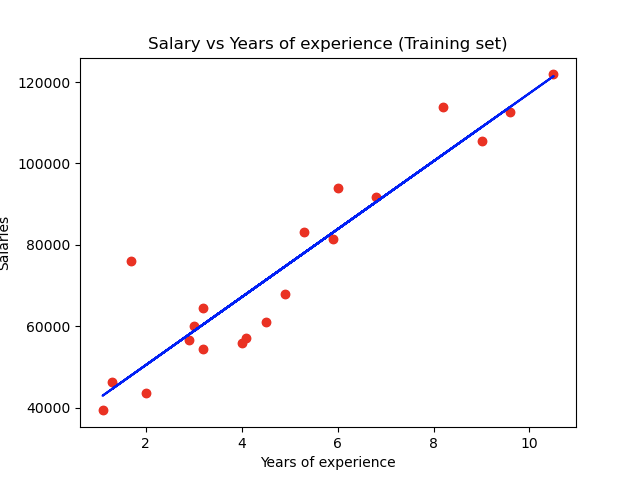
For this explanation, we have orientated ourselves on an idea from Askpython and modified it to suit our example.
Transfer Learning
Transfer learning is a good possibility to start trying out Neural Networks, as you don’t require the enormous amounts of data needed to train a really deep network. For example, you want to train a network to classify different kinds of plants, but you don’t have enough images of those plants to train a state-of-the-art convolutional network. In this case, you can load a pre-trained module, that will extract features, using its fixed weights that were trained on a large dataset. Once the features are extracted, the only thing you need to train is a simple classifier, which can be one or multiple fully connected layers. To train those, much less data is required, because there are fewer trainable parameters / weights, than in a complete network.
Both Tensorflow and PyTorch have multiple pretrained networks, so you can choose the architecture and compare how different frameworks perform on the same data.
Progress
The Machine Learning community is very big and growing, which produces an enormous amount of content to learn and improve in this field. If you are looking in something particular, there are a lot of tutorials floating around: from beginner to advanced levels, practical or theoretical.
But if you don’t know where to start and what to do next, an online course could be a good solution as it offers structure, examples, references. Platforms like Coursera, edX and Udemy offer such courses from universities across the world or from independent professionals.
Another possibility to improve your skills and understanding of data and Machine Learning is Kaggle. Kaggle is an online community of data science enthusiasts, where you can find all sorts of datasets and associated problems. For each task there is a challenge, which makes it more interesting as everyone tries to solve the problem better. There is also a possibility to look at and discuss the submissions of other users and that helps with improvement, by allowing to see all the different ideas that other people came up with.